SimCLR & SimCLR v2 논문 리뷰
SimCLR
1. Intro
Problem?
-
Human supervision 없이 visual representations를 학습하는 방법
-
그동안의 주된 접근 방법들은 Generative한 방법 혹은 Discriminative한 방법
- 하지만 computationally expensive하거나 pretext tasks의 사용으로 인한 generality 부족
Contrastive learning?
- 비슷한 elements에 대해서는 유사함, dissimilar elements에 대해서는 다름을 학습하는 방법
How?
- Multiple data augmentation operations
- Learnable nonlinear transformation
- Contrastive cross entropy loss
- Larger batch sizes and longer training
Method
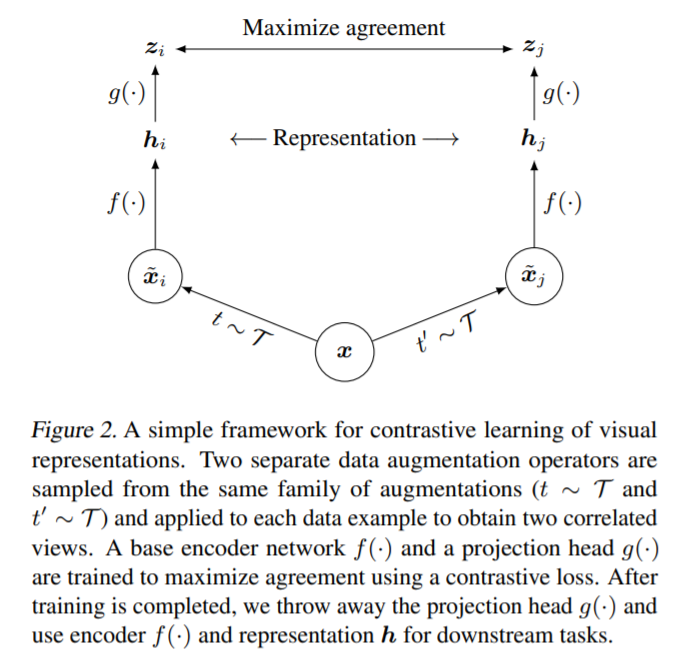
이를 조금 더 쉽게 표현하면 아래의 그림과 같음(출처: https://amitness.com/2020/03/illustrated-simclr/)
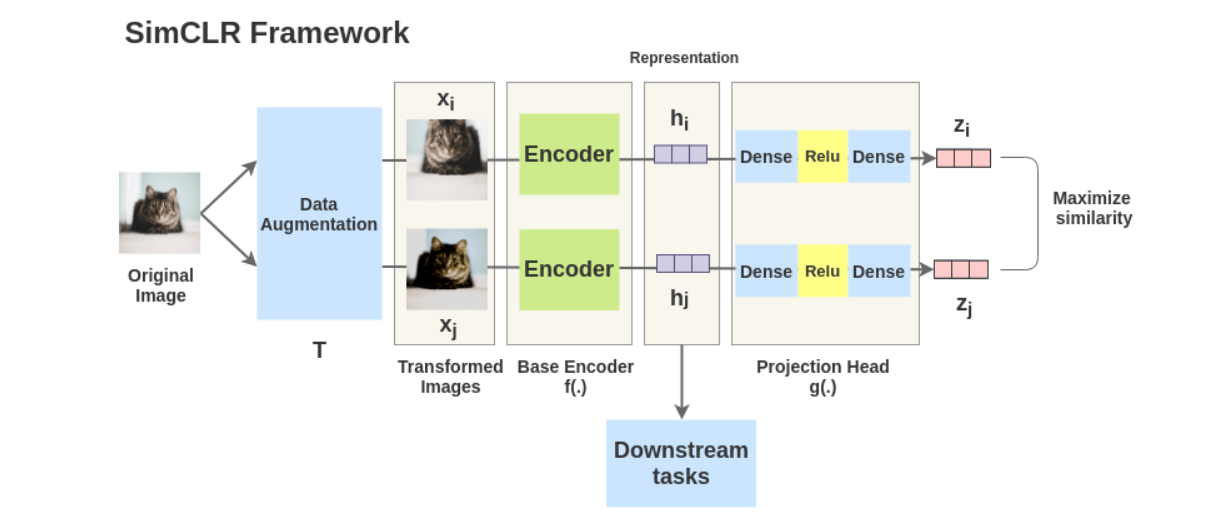
Procedure?
1) 같은 이미지에 대해서 stochastic한 data augmentation module을 통해서 augmented된 결과물 $\tilde{x}_i$와 $\tilde{x}_j$를 만듭니다.
2) 압선 결과물들을 base encoder $f(\cdot)$을 통과시켜 representation vectors를 각각 뽑아냅니다. 본 논문에서는 ResNet을 사용하였다고 합니다. 식으로는 $h_i=f(\tilde{x}_i)=ResNet(\tilde{x}_i)$이고 $h_i$의 경우 average pooling layer의 결과물로 보면 됩니다.
3) Projection head $g(\cdot)$을 사용하여 representation vectors를 mapping 시킵니다. 이때 MLP가 사용되며 식으로는 $z_i=g(h_i)=W^{(2)}\sigma(W^{(1)}h_i)$로 표현됩니다. (이때 $\sigma$는 ReLU를 의미) 2-layer MLP projection head를 사용하였다고 합니다.
4) Mapping이 이루어진 값 $z_i$와 $z_j$에 대해서 cosine similarity를 계산하고 이를 통해 contrastive loss function을 적용 (NT-Xent사용)

Algorithm?

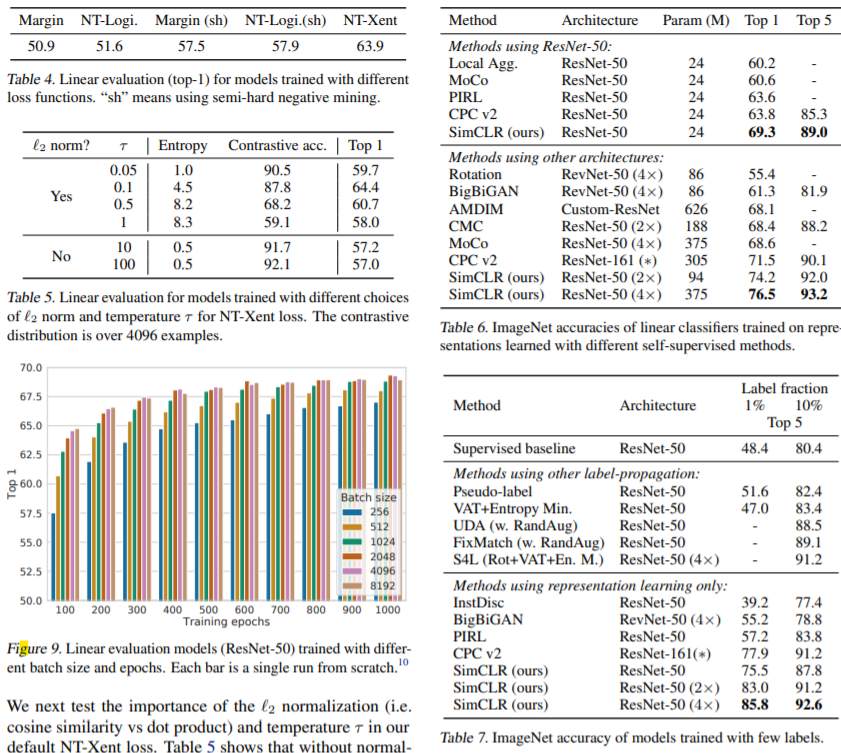
Batch size?
- Vary the batch size N from 256 to 8192
- 8192 batch size라면 ‘$8192\times 2-2=16382$’개의 negative samples가 존재
- 큰 batch size를 학습하기 위해 LARS optimizer
- 학습동안 aggregate BN mean and variance over all devices
Data augmentation?
- 좋은 결과를 위해서 data augmentation의 구성이 중요
- Supervised learning 보다 강한 augmentation이 필요
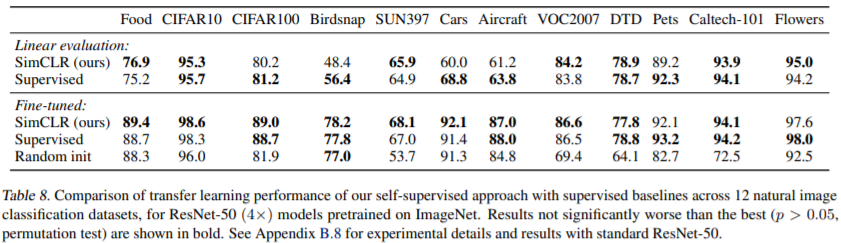
Experiments & Results
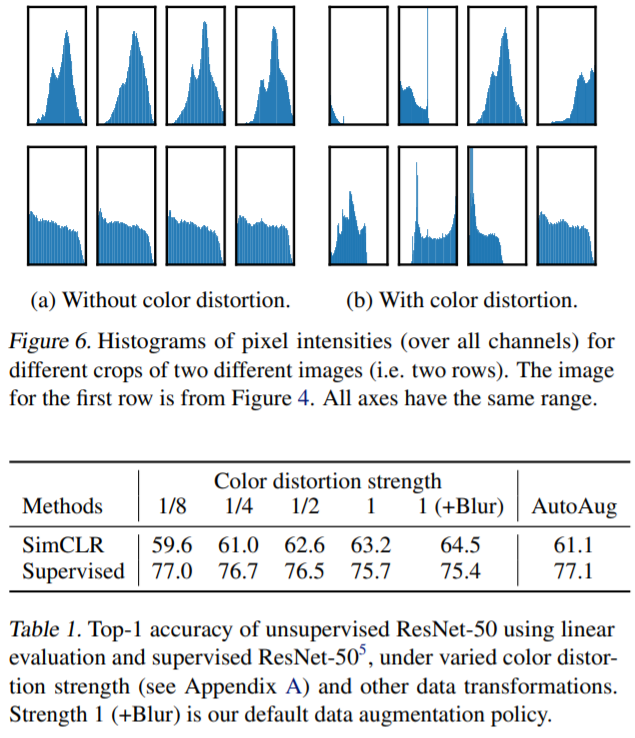
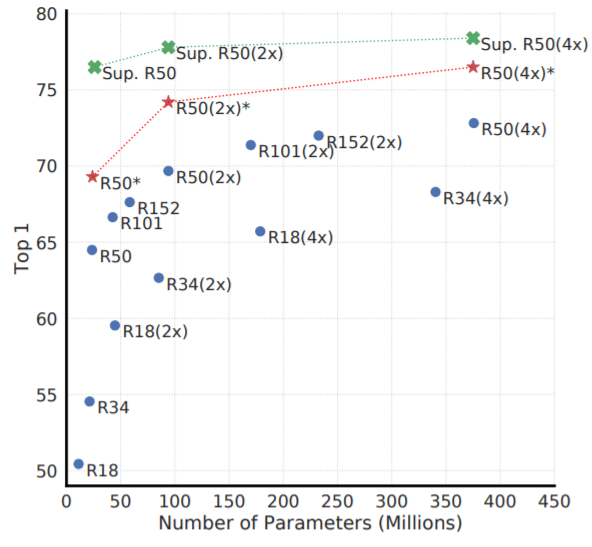
이해를 위한 추가적인 사이트: https://amitness.com/2020/03/illustrated-simclr/
SimCLR v2
Updating…
