StarGAN 논문 리뷰
StarGAN Review
1. Intro
Image-to-image translation 작업을 통해서 하나의 이미지를 특정한 특성에 따라 바꾸는 과정이 가능해졌습니다. 예를들어 이미지의 표정을 바꾸거나 사람 헤어스타일을 바꾸거나 성별을 바꾸는 등 다양한 특성에 대한 변화를 이끌어낼 수 있었습니다. 이때 성별, 헤어스타일과 같은 특성을 도메인이라고 하고 이러한 도메인을 가지는 이미지들을 하나씩 묶을 수 있습니다. 이전의 CycleGAN 논문에서 일반적인 말과 얼룩말이 있을때 이 특성을 변경시키는 과정을 진행했었습니다. 이때에는 일반적인 말 도메인과 얼룩말 도메인을 통해 image-to-image translation을 진행했던 것입니다. 이때 CycleGAN에서는 두 개의 generator와 cycle consistency loss를 사용하여 image-to-image translation 과정들을 진행했었습니다. 하지만 도메인들이 많아지면 어떻게 될까요? 서로 다른 도메인들에 적용하기 위하여 더 많은 generator가 필요할 것입니다.
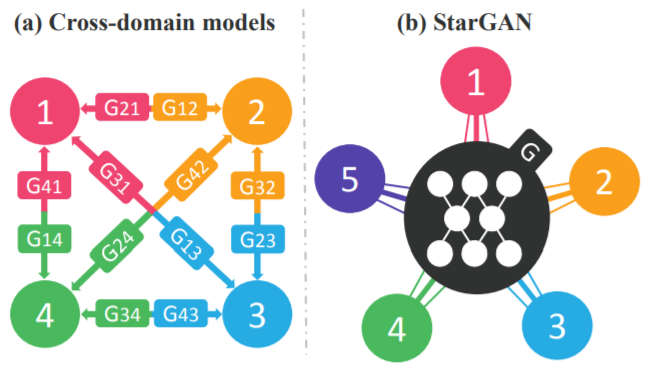
따라서 기존의 모델들을 사용했을시에는 효율적인 측면에서 부족한 점들이 있었습니다. CycleGAN과 같은 기존 모델의 경우 k개의 도메인이 존재할때 $k(k-1)$개의 generator가 필요했기 때문에 여러 개의 도메인에 대한 image translation에 있어서 매우 비효율적이라고 할 수 있습니다. 뿐만 아니라 기존의 모델들은 서로 다른 두 데이터셋을 함께 학습할 수 없다는 문제도 있습니다. 이러한 문제를 해결하여 하나의 generator로 여러 도메인을 한 번에 처리하고자 StarGAN이 도입되었습니다.

2. Architecture
2-1. Network
StarGAN은 CycleGAN에서 적용되었던 stride가 2인 두 개의 convolutional layers를 통한 downsampling과 transposed convolutional layers를 통한 upsampling을 진행합니다. 또한 generator에서 instance normalization을 진행합니다. Discriminator에서는 real과 fake를 구분하기 위하여 PatchGAN을 활용하였습니다.
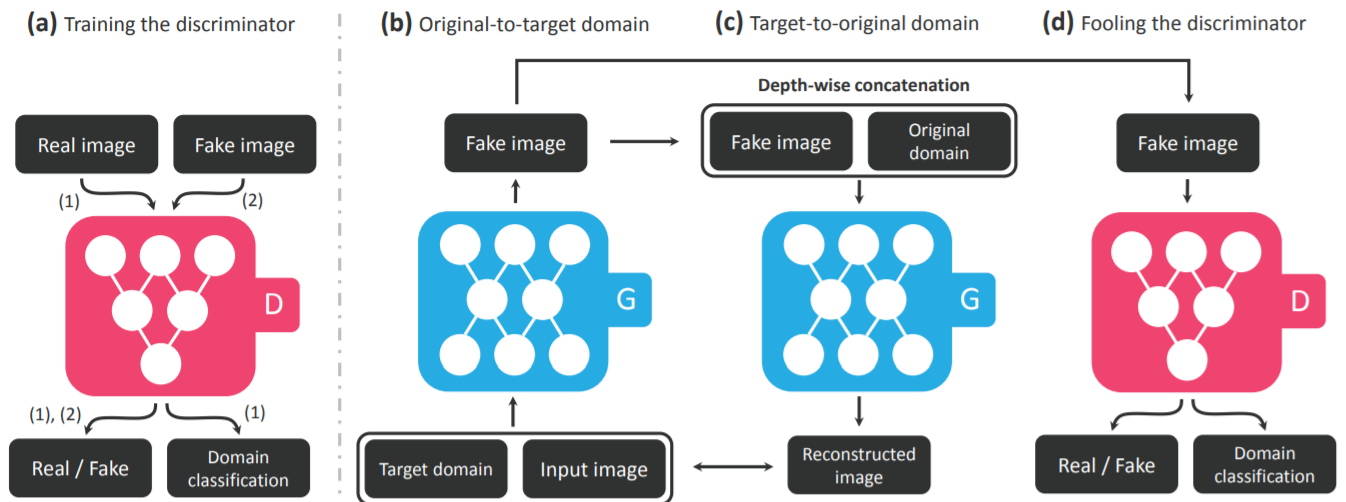
전체적인 구조는 위의 그림과 같습니다. Discriminator를 학습시에는 real image를 넣어주어 이미지가 real인지 fake인지 판단해주는 동시에 domain classification을 진행하고 fake image를 넣었을때에는 real인지 fake인지를 학습하는 과정을 거칩니다. 즉 discriminator는 이미지가 들어왔을때 real과 fake를 판단하도록, 또 그것이 real image인 경우 어떠한 도메인을 가지는지 학습을 하게 됩니다. Generator의 학습의 경우 input image와 target domain $c$를 generator에 넣어 fake image를 만들고 discriminator에 보내서 discriminator를 속이는 학습과정을 진행하며 fake image를 original domain $c’$을 다시 generator에 통과시켜 reconstructed image를 만들어 input image와 비교하는 학습도 진행을 하게 됩니다. 이때의 loss 함수들은 뒤에서 조금 더 다뤄보겠습니다.
2-2. Loss function
StarGAN에서는 크게 세 가지 종류의 loss function, adversarial loss, domain classification loss, reconstruction loss들을 활용하여 학습과 이미지 생성을 진행하였습니다.
Adversarial loss
\[\mathcal{L}_{adv} = \mathbb{E}_x[\log D_{src}(x)]+\mathbb{E}_{x, c}[\log (1-D_{src}(G(x,c)))]\]Adversarial loss를 통해 real image와 생성된 이미지를 구분할 수 없도록 해줍니다. 자세한 내용은 GAN을 참고하시면 좋을 것 같습니다.
Domain classification loss
\[\mathcal{L}^r_{cls} = \mathbb{E}_{x, c'}[-\log D_{cls}(c'|x)] \\ \mathcal{L}^f_{cls} = \mathbb{E}_{x, c}[-\log D_{cls}(c|G(x,c))]\]먼저 $\mathcal{L}^r_{cls}$를 살펴보면 이 loss값을 줄이므로써 discriminator가 실제 이미지 $x$를 original domain인 $c’$으로 분류하도록 학습하는 loss이며 반대로 $\mathcal{L}^f_{cls}$의 경우 loss값을 줄이므로써 generator가 생성한 이미지가 target domain $c$로 분류하도록 학습하는 loss입니다. 전자는 discriminator 학습에 사용이 되고 후자는 generator 학습 사용이 됩니다.
Reconstruction loss
\[\mathcal{L}_{rec} = \mathbb{E}_{x,c,c'}[\lVert x-G(G(x,c),c') \rVert_1]\]앞의 adversarial loss와 classification loss를 최소화하면서 G는 현실적인 이미지를 만들게 되었습니다. 하지만 실제와 같은 이미지가 되었더라도 그 이미지가 입력된 이미지의 content를 여전히 가지고 있는지에 대한 여부가 중요합니다. 따라서 이에 대한 해결을 위하여 CycleGAN에서 사용되었던 cycle consistency loss를 도입하였습니다. 이전의 architecture 그림처럼 input $x$에 대해서 $c$를 활용한 generator를 통과한 값을 다시 $c’$를 활용한 generator를 통과시켜 reconstructed image를 만들고 input image와의 차이를 loss로 활용하였습니다. 이때 L1 norm을 사용하였습니다.
Final
\[\mathcal{L}_D = -\mathcal{L}_{adv} + \lambda_{cls} \mathcal{L}^r_{cls} \\ \mathcal{L}_G = \mathcal{L}_{adv} + \lambda_{cls} \mathcal{L}^f_{cls} + \lambda_{rec}\mathcal{L}_{rec}\]최종적으로 D와 G에 대한 loss는 다음과 같습니다. 이때 $\lambda$값들은 하이퍼파라미터로 작용하여 각 loss의 중요도를 조절하게 되고 본 논문에서는 $\lambda_{rec}$와 $\lambda_{cls}$의 값을 각각 10과 1로 사용하였습니다.
2-3. Training with multiple datasets
앞서 StarGAN은 서로 다른 데이터셋에 대해서 적용이 가능하다고 언급을 했었습니다. 하지만 이는 간단한 작업은 아닙니다. 왜냐하면 데이터셋마다 그 labels가 다르기 때문입니다. 예를들어 본 논문에서 데이터로 사용하고 있는 CelebA와 RaFD의 경우 CelebA는 머리색, 성별 등의 labels를 가지는 반면 RaFD는 얼굴 표정이 주는 화남, 행복함 등의 감정을 labels로 두고 있습니다. 이를 해결하기 위해서 본 논문은 Mask vector라는 개념을 사용하였습니다. Mask vector의 경우 $\tilde{c} = [c_1, …, c_n]$로 표현을 하게 되는데 여기서 $c_i$값은 i번째 데이터셋을 말합니다. 예를들어 CelebA와 RaFD 데이터셋을 사용했을 경우 두 개의 데이터셋이므로 n=2가 되고 $c_1$이 CelebA, $c_2$가 RaFD 데이터를 나타내는 것으로 하여 진행할 수 있습니다. 따라서 특정 데이터셋에 대해 진행할시에는 mask vector를 통해 그 데이터셋을 사용한다는 것을 입력시켜주는 것입니다. 그림을 보시면 조금 더 잘 이해가 되실 수 있을겁니다.

다음 그림은 구조와 mask vector 및 label들을 활용한 것을 나타내고 있습니다. 위의 CelebA의 경우 mask vector를 $[1, 0]$ 반면 RaFD의 경우 $[0, 1]$을 사용하고 있는 것을 알 수 있습니다. 이처럼 mask vector의 사용하게 되면 사용하지 않는 label들은 ?로 표현이 됨을 알 수 있습니다. 즉 어떠한 데이터셋을 사용할지 조정이 가능하다는 것입니다. 노란색 label과 초록색 label의 경우에는 각각 CelebA와 RaFD의 도메인을 담는 vector라고 보시면 될 것 같습니다.
그림의 아랫부분(RaFD)을 살펴보면 discriminator의 학습이 진행되고 generator 학습에서는 ‘happy’ label을 사용하여 fake image를 만들고 만든 이미지를 discriminator에 넣어 real/fake 여부 판단과 RaFD label의 어떠한 영역에 속하는지 판단하는 과정, ‘angry’ label을 사용하여 reconstructed image를 만들어 처음 사진과 비교하는 것을 보시면 어떻게 학습을 진행하였는지 감이 오실꺼라고 생각합니다.
3. Experiments and Results
3-1. Setting
- CelebA dataset - 128$\times$128 이미지로 resize, 7개의 도메인 활용
- RaFD dataset
- Adam optimizer with $\beta_1=0.5$, $\beta_2=0.999$
- Horizontal flip as an augmentation
- 한 번의 generator 업데이트를 할 동안 5번의 discriminator 업데이트
- Decaying learning rate
3-2. CelebA
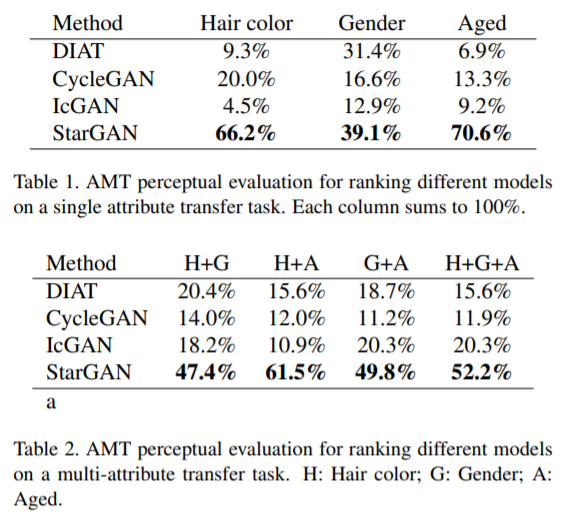
CelebA 데이터를 사용하여서 결과를 냈을때 다음과 같은 결과값들을 보여주었습니다. 위의 표는 단일 속성에 대한 결과값이면 아래의 표는 두 개 이상의 속성을 가지고 평가한 값들입니다. 평가 지표로는 Amazon Mechanical Turk(AMT)를 활용하였다고 합니다. 보시다시피 StarGAN이 다른 방법들에 비해서 좋은 결과를 보여주는 것을 확인하였습니다.

CelebA 데이터의 결과물을 이미지로 표현하면 다음과 같았습니다.
3-3. RaFD

다른 모델들과 비교하였을 때 StarGAN의 classification error가 다른 비교모델들보다 낮은 동시에 파라미터 수도 현저하게 낮은 것을 알 수 있었습니다.

가시화된 결과물은 다음과 같았습니다.
3-4. CelebA & RaFD
마지막으로는 논문에서 두 데이터셋을 동시에 학습을 시키는 결과물이 있었습니다. 이때 이전에 언급했던 mask vector의 사용이 이루어집니다. 그 예시로는 아래의 그림을 볼 수 있을 것 같습니다. 위에 있는 그림들이 mask vector를 적절히 사용한 결과물들이고 아래의 그림들은 mask vector를 적절히 사용하지 못한 결과물입니다. 이것을 통하여 mask vector를 제대로 사용하지 않는다면 real image인지 fake image인지를 discriminator가 판단하기 어려울만큼 잘 만들어낼 수 있지만 도메인에 대한 문제가 생길 수 있다는 것을 확인할 수 있는 결과를 보여주었습니다.

